| Niveau de difficulté | Facile |
| Privilèges de la racine | Non |
| Exigences | Terminal Linux ou Unix |
| Catégorie | Recherche |
| Conditions préalables | commande egrep |
| Compatibilité avec les systèmes d'exploitation | BSD-Linux-macOS-Unix-WSL |
| Durée de lecture estimée | 8 minutes |
Expressions régulières dans grep
Les expressions régulières ne sont rien d'autre qu'un modèle à faire correspondre à chaque ligne d'entrée. Un motif est une séquence de caractères. Les exemples suivants sont des exemples de motifs :
^w1 w1|w2 [^ ] foo bar [0-9]
Trois types de regex
Le grep comprend trois types différents de syntaxe d'expression régulière, comme suit :
- de base (BRE)
- étendu (ERE)
- perl (PCRE)
Exemples d'expressions régulières grep
Recherchez un mot nommé 'vivek' dans le fichier /etc/passwd :
$ grep vivek /etc/passwdExemples de résultats :
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash vivekgite:x:1001:1001::/home/vivekgite:/bin/sh gitevivek:x:1002:1002::/home/gitevivek:/bin/sh
Ensuite, recherchez un mot nommé 'vivek' dans n'importe quelle casse (c'est-à-dire une recherche insensible à la casse) :
$ grep -i -w vivek /etc/passwdEssayons de rechercher les deux mots 'vivek' ou 'raj' dans tous les cas :
$ grep -E -i -w vivek|raj /etc/passwdLe PATTERN du dernier exemple, utilisé comme une expression régulière étendue. Ce qui suit correspondra au mot Linux ou UNIX dans tous les cas en utilisant la commande egrep :
$ egrep -i ^(linux|unix) filename
# Same as above by passing the -E to the grep #
$ grep -E -i ^(linux|unix) filenameComment faire correspondre des caractères uniques
Le site . (point, ou point) correspond à un caractère quelconque. Considérons le fichier demo.txt suivant :
$ cat demo.txtExemples de résultats :
foo.txt bar.txt foo1.txt bar1.doc foobar.txt foo.doc bar.doc dataset.txt purchase.db purchase1.db purchase2.db purchase3.db purchase.idx foo2.txt bar.txt
Trouvons tous les noms de fichiers commençant par "achat", type :
$ grep purchase demo.txtEnsuite, je dois trouver tous les noms de fichiers commençant par un achat et suivis d'un autre caractère :
$ grep purchase.db demo.txtNotre dernier exemple trouve tous les noms de fichiers commençant par purchase et se terminant par db :
$ grep purchase..db demo.txt 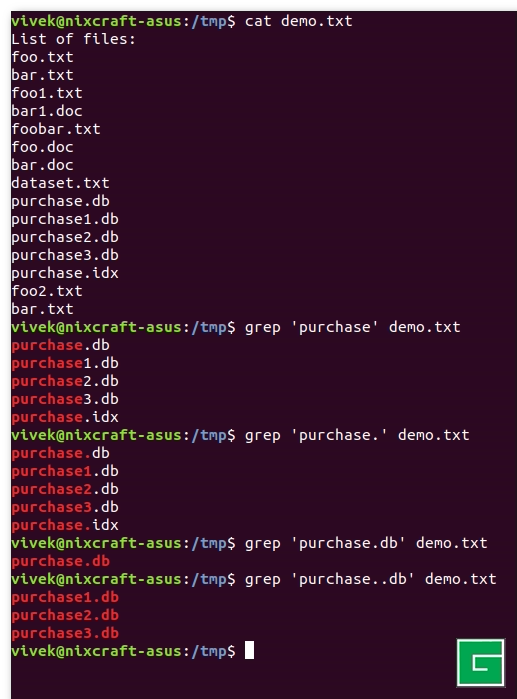
Comment faire correspondre seulement le point (.)
Le point (.) a une signification particulière dans les regex, c'est-à-dire qu'il peut correspondre à n'importe quel caractère. Mais, que se passe-t-il si vous avez besoin de faire correspondre le point (.) uniquement ? Je veux dire à ma commande grep que je veux le caractère point (.) réel et non la signification spéciale de regex du caractère . (point). Vous pouvez échapper au point (.) en le faisant précéder d'une (backslash) :
$ grep purchase.. demo.txt
$ grep purchase.. demo.txt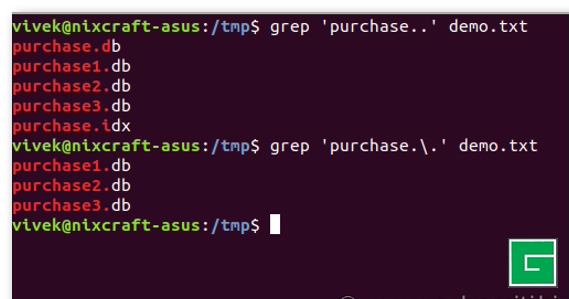
Ancres
Vous pouvez utiliser ^ et $ pour forcer une regex à ne correspondre qu'au début ou à la fin d'une ligne, respectivement. L'exemple suivant affiche uniquement les lignes commençant par le mot vivek :
$ grep ^vivek /etc/passwdExemples de résultats :
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
Vous pouvez afficher uniquement les lignes commençant par le mot vivek, c'est-à-dire ne pas afficher vivekgite, vivekg, etc :
$ grep -w ^vivek /etc/passwdTrouvez les lignes se terminant par le mot foo :
$ grep foo$ filenameCorrespond à la ligne contenant uniquement foo :
$ grep ^foo$ filenameVous pouvez rechercher des lignes vides à l'aide des exemples suivants :
$ grep ^$ filenameFaire correspondre des ensembles de caractères
Comment faire correspondre des ensembles de caractères en utilisant grep
Le point (.) correspond à tout caractère unique. Vous pouvez faire correspondre des caractères spécifiques et des plages de caractères en utilisant la syntaxe [...]. Supposons que vous vouliez faire correspondre 'Vivek' ou 'vivek' :
$ grep [vV]ivek filenameOU
$ grep [vV][iI][Vv][Ee][kK] filenameFaisons correspondre les chiffres et les caractères majuscules et minuscules. Par exemple, essayez de faire correspondre des mots tels que vivek1, Vivek2 et ainsi de suite :
$ grep -w [vV]ivek[0-9] filenameDans cet exemple, la correspondance porte sur deux chiffres. En d'autres termes, faites correspondre foo11, foo12, foo22 et ainsi de suite, entrez :
$ grep foo[0-9][0-9] filenameVous n'êtes pas limité aux chiffres, vous pouvez faire correspondre au moins une lettre :
$ grep [A-Za-z] filenameAffiche toutes les lignes contenant un caractère "w" ou "n" :
$ grep [wn] filenameDans une expression entre crochets, le nom d'une classe de caractères entouré de "[ :" et " :]" représente la liste de tous les caractères appartenant à cette classe. Les noms de classes de caractères standard sont les suivants :
- [[:alnum :]] - Caractères alphanumériques.
- [[:alpha :]] - Caractères alphabétiques
- [[:blanc :]] - Caractères vides : espace et tabulation.
- [[:chiffre :]] - Chiffres : "0 1 2 3 4 5 6 7 8 9".
- [[:inférieur :]] - Lettres minuscules : "a b c d e f g h i j k l m n o p q r s t u v w x y z".
- [[:espace :]] - Caractères d'espacement : tabulation, nouvelle ligne, tabulation verticale, saut de page, retour chariot et espace.
- [[:supérieur :]] - Lettres majuscules : "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".
Dans cet exemple, faites correspondre toutes les lettres majuscules :
$ grep [:upper:] filenameComment les négations correspondent dans les ensembles
Le ^ annule toutes les plages d'un ensemble :
$ grep [vV]ivek[^0-9] test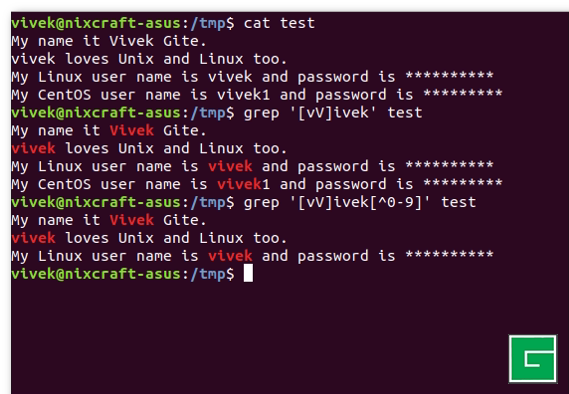
Utilisation des expressions régulières grep pour rechercher des modèles de texte
Wildcards
Vous pouvez utiliser le "." pour une correspondance à un seul caractère. Dans cet exemple, il s'agit d'un mot de 3 caractères commençant par "b" et se terminant par "t" :
grep '' filename
Où,
- >>>>>>>> Correspond à la chaîne vide à la fin du mot.
Imprimer toutes les lignes contenant exactement deux caractères :
$ grep ^..$ filenameAffichez toutes les lignes commençant par un point et un chiffre :
$ grep ^.[0-9] filenameEchapper au point
Supposons que vous souhaitiez uniquement faire correspondre une adresse IP 192.168.2.254 et rien d'autre. La regex suivante pour trouver l'adresse IP 192.168.1.254 ne fonctionnera pas (rappelez-vous que le point correspond à tout caractère unique) :
$ grep 192.168.1.254 hostsExemples de résultats :
192.168.2.18 centos7 192x168y2z18 centos7
Les trois points doivent être échappés :
192.168.2.18 centos7
$ grep 192.168.1.254 hostsL'exemple suivant ne correspondra qu'à une adresse IP :
$ egrep [[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3} fileComment puis-je rechercher un motif qui a un fil conducteur ? - Un symbole ?
Recherche toutes les lignes correspondant à '--test--en utilisant -e option Sans -egrep tentera d'analyser '–test–comme une liste d'options. Par exemple :
$ grep -e --test-- filenameComment faire un OR avec grep ?
Utilisez la syntaxe suivante :
$ grep -E word1|word2 filename
### OR ###
$ egrep word1|word2 filenameOU Essayez la syntaxe suivante :
$ grep word1|word2 filenameComment puis-je ET avec grep ?
Utilisez la syntaxe suivante pour afficher toutes les lignes qui contiennent à la fois 'mot1' et 'mot2'.
$ grep word1 filename | grep word2OU essayez la syntaxe suivante :
$ grep foo.*bar|word3.*word4 filenameComment tester une séquence ?
Vous pouvez tester la fréquence à laquelle un caractère doit être répété dans une séquence en utilisant la syntaxe suivante :
{N}
{N,}
{min,max}Faites correspondre un caractère "v" deux fois :
$ egrep v{2} filenameLe texte suivant correspondra à la fois aux mots "col" et "cool" :
$ egrep co{1,2}l filenameL'exemple suivant correspondra à toute ligne contenant au moins trois lettres 'c'.
$ egrep c{3,} filenameDans cet exemple, je vais faire correspondre le numéro de téléphone mobile au format suivant : 91-1234567890 (c'est-à-dire deux chiffres et dix chiffres).
$ grep [[:digit:]]{2}[ -]?[[:digit:]]{10} filenameComment mettre en évidence avec grep ?
Passez le --color comme suit :
$ grep --color regex filenameComment afficher uniquement les correspondances et non les lignes ?
Utilisez la syntaxe suivante :
$ grep -o regex filenamegrep Opérateur d'expression régulière
J'espère que le tableau suivant vous aidera à comprendre rapidement les expressions régulières dans grep lorsque vous l'utilisez sous Linux ou des systèmes similaires à Unix :
| . | Correspond à n'importe quel caractère unique. | grep '.' file grep 'foo.' input |
| ? | L'élément précédent est facultatif et sera apparié, au maximum, une fois. | grep 'vivek?' /etc/passwd |
| * | L'élément précédent sera apparié zéro fois ou plus. | grep 'vivek*' /etc/passwd |
| + | L'élément précédent sera apparié une ou plusieurs fois. | ls /var/log/ | grep -E "^[a-z]+.log." |
| {N} | L'élément précédent est apparié exactement N fois. | egrep '[0-9]{2} input |
| {N,} | L'élément précédent est apparié N fois ou plus. | egrep '[0-9]{2,} input |
| {N,M} | L'élément précédent est apparié au moins N fois, mais pas plus de M fois. | egrep '[0-9]{2,4} input |
| - | Représente la plage si elle n'est pas la première ou la dernière dans une liste ou le point final d'une plage dans une liste. | grep ':/bin/[a-z]*' /etc/passwd |
| ^ | Correspond à la chaîne vide au début d'une ligne ; représente également les caractères qui ne sont pas dans la plage d'une liste. | grep '^vivek' /etc/passwd grep '[^0-9]*' /etc/passwd |
| $ | Correspond à la chaîne vide à la fin d'une ligne. | grep '^$' /etc/passwd |
| b | Correspond à la chaîne vide au bord d'un mot. | grep 'bvivek' /etc/passwd |
| B | Correspond à la chaîne vide, à condition qu'elle ne soit pas au bord d'un mot. | grep 'B/bin/bash' /etc/passwd |
| Correspond à la chaîne vide au début du mot. | grep ' | |
| >> | Correspond à la chaîne vide à la fin du mot. | grep 'bash>' /etc/passwd grep ' |
Commande Linux grep vs egrep
L'egrep est le même que grep -E commande. Elle interprète PATTERN comme une expression régulière étendue. Extrait de la page de manuel grep :
In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions ?, +, {,
|, (, and ).
Traditional egrep did not support the { meta-character, and some egrep implementations support { instead, so portable scripts should avoid { in
grep -E patterns and should use [{] to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification.
For example, the command grep -E '{1' searches for the two-character string {1 instead of reporting a syntax error in the regular expression.
POSIX.2 allows this behavior as an extension, but portable scripts should avoid it.
Conclusion
Vous avez appris à utiliser les expressions régulières (regex) dans grep sous Linux ou Unix avec divers exemples. Consultez la page de manuel de GNU/grep en ligne ici ou consultez les ressources suivantes en utilisant la commande man ou la commande info (ou passez l'option --help :
$ man egrep
$ info egrep
$ man 7 regex
$ egrep --help<